





brain of mat kelcey...
an exercise in handling mislabelled training data
October 03, 2011 at 08:00 PM | categories: Uncategorizedintro
as part of my diy twitter client project i've been using the twitter sample streams as a source of unlabelled data for some mutual information analysis. these streams are a great source of random tweets but include a lot of non english content. extracting the english tweets would be pretty straight forward if the ['user']['lang'] field of a tweet was 100% representative of the tweet's language but a lot of the times it's not; can we use these values at least as a starting point?
one approach to seeing how consistent the relationship between user_lang and the tweet language is to
- train a classifier for predicting the tweet's language assuming the user_lang field is correct
- have the classifier reclassify the same tweets and see which ones stand out as being misclassified
yes, yes, i realise that testing against the same data you've trained against is a big no no but i'm curious...
method
let's start with 100,000 tweets taken from the sample stream. we'll use vowpal wabbit for the classifier and extract features as follows...
- lower case the tweet text.
- remove hashtags, user mentions and urls.
- split the text into character unigrams, bigrams and trigrams.
we treat tweets marked as user_lang=en as the +ve case for the classifier (class 1) and all other tweets as the -ve case (class 0).
the standard output for predictions from vowpal is a value from 0.0 (not english) to 1.0 (english) but we'll use the raw prediction values instead; the magnitude of these in some way describes the model's confidence in the decision.
results
when we reclassify the tweets the model does pretty well (not surprisingly given we're testing against the same data we trained against)
some examples include..
tweet text watching a episode of law & order this sad awww marked english? 1.0 ( yes ) raw prediction 0.998317 ( model agrees it's english ) tweet text こけむしは『高杉晋助、沖田総悟、永倉新八、神威、白石蔵ノ介』に誘われています。誰を選ぶ? marked english? 0.0 ( marked as ja ) raw prediction -1.06215 ( model agrees, definitely not english )
it's not getting 100% (what classifier ever can?) and in part it's since the labelling is "incorrect" at times.
we can use perf to check the accuracy of the model (though it's not really checking "accuracy", more like checking "agreement") and doing this we can see the classifier is correct roughlty 82% of the time.
> accuracy [1] 0.82496 0.81260 0.82690 0.82654 0.82454 0.82354 0.82078 0.82023 0.82120 0.81990 > summary(accuracy) Min. 1st Qu. Median Mean 3rd Qu. Max. 0.8126 0.8204 0.8224 0.8221 0.8249 0.8269
(see evaluate.sh for the code to reproduce this)
analysis
so it generally does well but the most interesting cases are when the model doesn't agree with the label.
tweet text [천국이 RT이벤트]2011 대한민국 소비자신뢰 대표브랜드 대상수상! 알바천국이 여러분의 사랑에힘입어 marked english? 1.0 ( hmmm, not sure this is in english :/ ) raw prediction -0.52598 ( ie model thinks it's not english ) "disagreement" 1.52598
this is great! the model has correctly identified this instance is mislabelled. however sometimes the model disagrees and is wrong...
tweet text поняла …что она совсем не нужна ему. marked english? 0.0 ( fair enough, looks russian to me.. ) prediction: 5.528163 ( model strongly thinks it's english ) "disagreement" 5.528163
a bit of poking through the tweets shows that there are enough russian tweets marked as english for it to be learnt as english...
"correcting" the labels
we can score each tweet based on how much the model disagrees (mean square error of "disagreement" across the multiple runs) and we see, at least for the top 200, that the model was right the vast majority of the time (ie the language of the tweet isn't the user_lang).
what we can do then is trust the model and change the user_lang as required for the top, say, 100 and reiterate.
if we do this overall iteration 10 times we see a gradual improvement in the model.
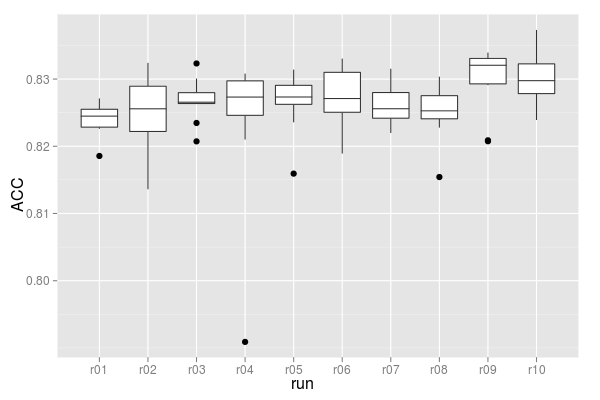
comparing the first run (r01) to the last (r10) the mean has risen a little bit from 0.8245 to 0.8298 and a t-test thinks this change is significant (p-value = 0.002097 < 0.05); though it's not really that huge an improvement
but an even simpler solution
the iterative solution was novel but it turns out there's a much better solution; make a first pass on the data and if you see one of the common non english characters и, の, ل or น just mark the tweet as non english.
if we do this we get an immediate improvement
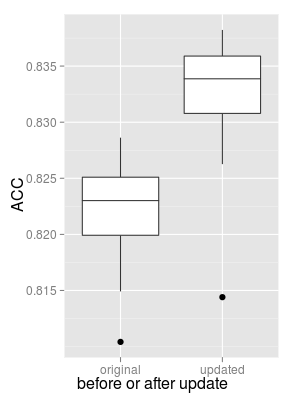
> summary(updated) Min. 1st Qu. Median Mean 3rd Qu. Max. 0.8144 0.8308 0.8339 0.8326 0.8359 0.8382
and you don't need a t-test to see this change is significant :)
tl;dr
- a supervised classifier can be used in an iterative sense to do unsupervised work
- but never forget a simple solution can often be the best!