





brain of mat kelcey...
do all first links on wikipedia lead to philosophy?
August 13, 2011 at 03:00 PM | categories: projectsquestions
a recent xkcd posed the idea...
wikipedia trivia: if you take any article, click on the first link in the article text not in parentheses or italics, and then repeat, you will eventually end up at Philosophy.
this raises a number of questions
- Q: though i wouldn't be surprised if it's true for most articles it can't be true for all articles. can it?
- Q: what's the distribution of distances (measured in "number of clicks away") from 'Philosophy'?
- Q: by this same measure what's the furthest article from 'Philosophy'?
- Q: are there any other articles that are more common than 'Philosophy'?
- Q: what are the common paths to 'Philosophy'?
there's only one way to find out!
- grab a wikipedia dump
- build the graph of 'article' to 'first link to next article' (not in parentheses or italics)
- do breadth first search backwards from 'Philosophy' and see what things look like
getting and processing the data
for my first attempt i tried to use the freebase wikipedia dump. my thought was it'd be easier to deal with a preparsed dataset but it didn't turn out.
two big problems....
- lots of information has been lost in the preparsing (eg. it was sometimes hard to determine if the first links were from the main body of text or from a sidebar )
- some pages weren't parsed properly at all and were just blank; included ones like Greeks which ended up being pretty important.
instead i went for a raw wikimedia dump, in particular enwiki-latest-pages-articles.xml.bz2. the version at the time of writing this blog was 7gb compressed & 30gb uncompressed. it's already up to 9gb as of Feb 2013!
for preprocessing there were a number of steps
- split the dataset into pages that represent redirects and the actual articles themselves
- dereference all the redirects (to avoid redirects that redirect to other redirects)
- parse all the articles; the crux of this is done with mwlib and article_parser.py; to make a big list of edges of 'from' nodes (the article) and 'to' nodes (the first applicable link on the article page)
- dereference the edges to make sure all redirects have been followed
some general statements before we go further
- wikipedia is under heavy edit churn. i've been doing this project in 15-30 minutes chunks for a few weeks and it's amazing how often i'd compare the parsing to live wikipedia and find out a page had already subtely changed. god knows what it looks like currently.
- i wrote all the code for this in python as i'm trying to move away from ruby to get better data related library support. everything in fact except for the depth first search which i did in java. the full graph as a dict was insanely slow to access, i must be doing something wrong. for the full details see the code on this project. git cloning the project and executing the README as a shell script may [1] do something close to all the steps from start to finish. [1] or it might not
the end result of the parsing is a list of 3.6e6 edges of the form 'article' -> 'first link to next article' (after following redirects).
all the 'article's are unique but there are only 500e3 distinct 'next article's which is already very interesting; it means less than 15% of articles on wikipedia are represented by one of these first links; this graph is very "bushy" (ie lots of leaf nodes).
to calculate the distance from 'Philosophy' for all articles it's a straight forward breadth first search and because this search doesnt cycle back to 'Philosophy' again it ends up building a tree.
the results
with this tree we can start answering some of our original questions ...
Q: though i wouldn't be surprised if it's true for most articles it can't be true for all articles. can it?
seems it's not true for all articles; 3.5e6 articles lead to 'Philosophy' but 100e3 don't.
these 100e3 fall into two types
1) 50e3 of them end up in cycles. this is a remarkably low count given 3.5e6 make it to 'Philosophy'.
the vast majority of the cycles are of length 2; eg Waste management -> Waste collection -> Waste management
( my favorite that i stumbled across is Sand fence -> Snow fence -> Sand fence the first sentence of Snow fence being "A snow fence is a structure, similar to a sand fence ..." the first sentence of Sand fence being "A sand fence is a structure similar to a snow fence ..." )
2) the other 50e3 are dead ends; all sorts of examples for this, mainly around pages that were never written or have been deleted.
eg Windsurfing -> Surface water sports -> Discing (which has deleted)
Q: what's the distribution of distances of articles from 'Philosophy'?
the bulk of the articles are between 10 to 30 clicks away...
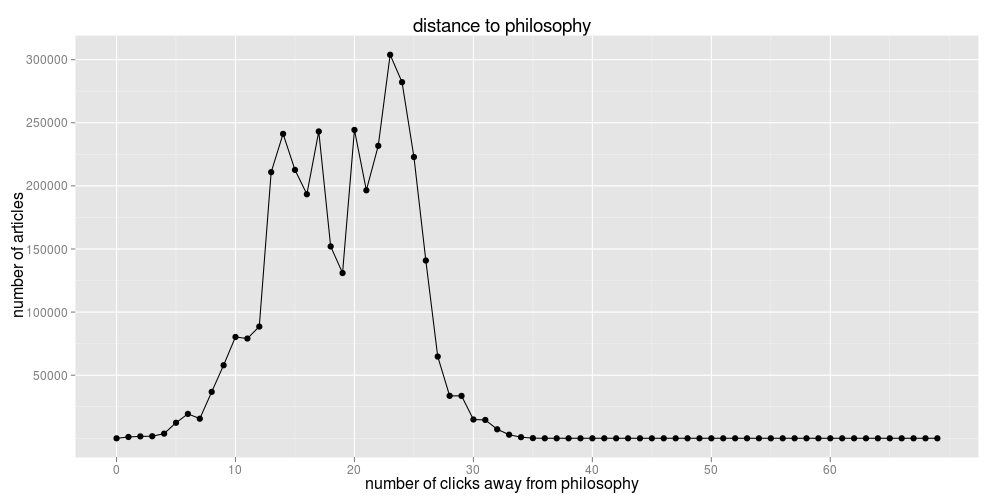
i've trimmed this graph at 70 clicks away since there's a long tail of one single path that is 1001 articles long.
List of state leaders in 1977 -> List of state leaders in 1976 -> List of state leaders in 1975 -> .... -> List of state leaders in 1001 -> List of state leaders in 1000 -> Fatimid Caliphate -> Arab people -> Panethnicity -> Ethnic group -> Social group -> Social sciences -> List of academic disciplines -> Academia -> Community -> Living -> Life -> Physical body -> Physics -> Natural science -> Science -> Knowledge -> Fact -> Information -> Sequence -> Mathematics -> Quantity -> Property (philosophy) -> Modern philosophy -> Philosophy
seems a bit of a "meta article" outlier we can ignore.
( there's an interesting dip at a distance of 19 too; wonder what's going on there? )
Q: what's the furthest article from 'Philosophy'?
'Violet & Daisy' is the longest chain i found that didn't include "meta" pages with some kind of sequence number in it. it's 36 articles from 'Philosophy'.
Violet & Daisy -> Saoirse Ronan -> BAFTA Award for Best Actress in a Supporting Role -> British Academy Film Awards -> British Academy of Film and Television Arts -> David Lean -> Order of the British Empire -> Chivalric order -> Knight -> Warrior -> Combat -> Violence -> Psychological manipulation -> Social influence -> Conformity -> Unconscious mind -> Germans -> Germanic peoples -> Proto-Indo-Europeans -> Proto-Indo-European language -> Linguistic reconstruction -> Internal reconstruction -> Language -> Human -> Extant taxon -> Biology -> Natural science -> Science -> Knowledge -> Fact -> Information -> Sequence -> Mathematics -> Quantity -> Property (philosophy) -> Modern philosophy -> Philosophy
Q: are there any other articles that are "more common" than 'Philosophy'?
with 95+% of articles clicking through to 'Philosophy' it's not possible for there to be another unconnected graph with an article more represented than 'Philosophy'.
but if we continue to click through past 'Philosophy' we see we're in a short cycle of 12 articles...
Philosophy -> Reason -> Natural science -> Science -> Knowledge -> Fact -> Information -> Sequence -> Mathematics -> Quantity -> Property (philosophy) -> Modern philosophy -> Philosophy
so really any of these are reasonable candidates and are equally good as 'Philosophy' itself for this game.
Q: what are the common paths into 'Philosophy'?
as mentioned the breadth first search builds a tree of articles with 'Philosophy' at it's root.
one metric we can assign to each article in this tree is the number of descendant articles it has. 'Philosophy', as the root, has all articles as descendants so it's number is 3.5e6 and it's rank 1. the next ranked by number of descendants is 'Modern philosophy' with 3.4e6 descendants; ( ie of the 3.5e6 articles that eventually led to 'Philosophy' only 100e3 of them didn't click through 'Modern Philosophy').
by ranking articles by this metric we can observe the core structure of the tree.
in fact for the top 10 ranked articles it's hardly a tree, just the chain ...

(width of the edge is proportional to the number of descendants)
it turns out that 3e6 articles (85% of the lot) get to 'Philosophy' through 'Science'.
in fact it's not until we consider up to the 20th ranked item, 'Biology', before it actually becomes a tree structure ...

(click for a bigger version)
when we consider the top 200 things start to look a bit more interesting ...
and by the top 1000 things are starting to lose an obvious core structure ...
( though dot's a pretty poor layout engine for this one, i should redo this one )
conclusions
so i managed to answer the main questions i had, but it's a fun dataset so there's lots more to do yet!
todos include
- a better layout for the top 1000 or so
- redo with a more recent wiki dump to see what's changed
- what happened at a depth of 19 articles?