





brain of mat kelcey...
trending topics in tweets about cheese; part1
April 27, 2010 at 11:42 PM | categories: Uncategorizedtrending topics
what does it mean for a topic to be 'trending'? consider the following time series (430e3 tweets containing cheese collected over a month period bucketed into hourly timeslots)
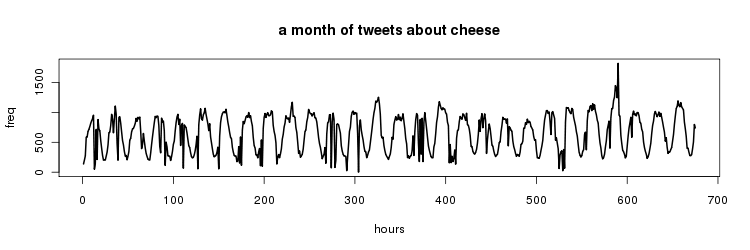
without a formal definition we can just look at this and say that the series was trending where there was a spike just before time 600. as a start then let's just define a trend as a value that was greater than was 'expected'.
how can we calculate trending?
one really nice simple algorithm for detecting a trend is to say a value, v, is trending if v > mean + 3 * standard deviation of the data seen so far.
i've since found an even simpler one version is to calculate a trending score = ( v - mean ) / std dev. the higher the score, the more the trendingness.
let's consider the same time series as before but this time with some overlaid data; green - the mean red - minimum trend value ( = mean + 3 * std dev ) blue - instances where the value > minimum trend value
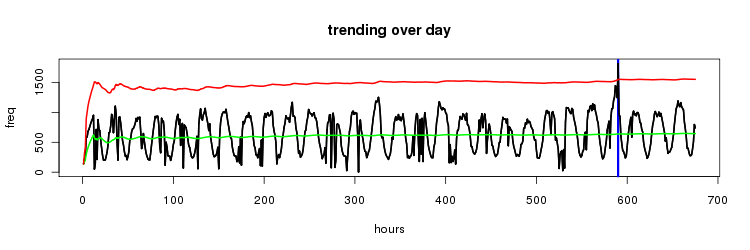
here's a zoom in on the last 200 values
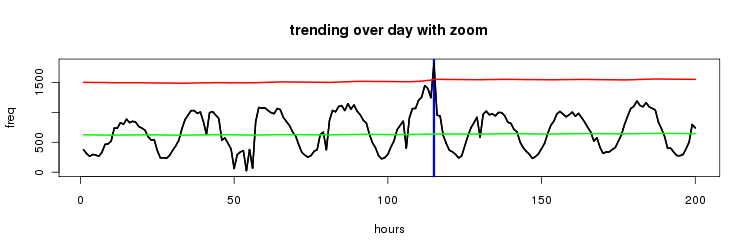
this works surprisingly well, the mean gives a solid expectation of the value with the standard deviation covering the daily periodic nature of the data.
it's not perfect though as this system only ever allows a trend around the peaks of the cycle.
for example consider the troughs which have a frequency value around 250. if we had a value in one of those timeslot's that was 1000, ie four times what was expected given that time of day, it would not be considered trending since the value has to be over 1500
facet by hour
one way to handle this is to not have a single time series but instead maintain 24 time series, one for each hour of the day.
faceting in this way gives the following trending
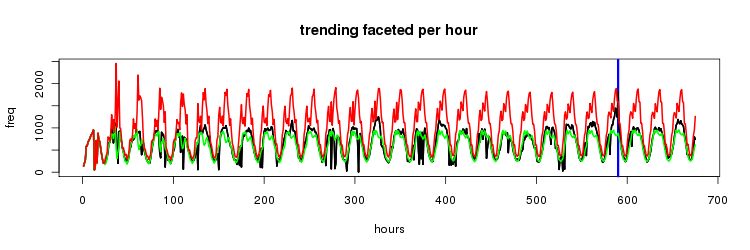
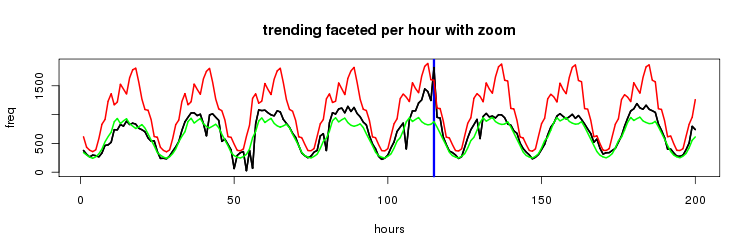
and though this doesn't present any cases of trends at a trough we can see it was prettttty close a number of times.
facet by ngram
one other interesting way to facet, and the main purpose of this project, is to maintain a seperate time series for each ngram in the tweet.
the top 10 2-grams in my dataset are...
| freq | term1 | term2 |
| 44389 | and | cheese |
| 33454 | cheese | and |
| 22815 | mac | cheese |
| 22532 | grilled | cheese |
| 18639 | cream | cheese |
| 15225 | the | cheese |
| 13592 | mac | and |
| 12967 | chuck | cheese |
| 12598 | of | cheese |
| 12296 | cheese | on |
let's look at the time series for a few of them.
grilled cheese
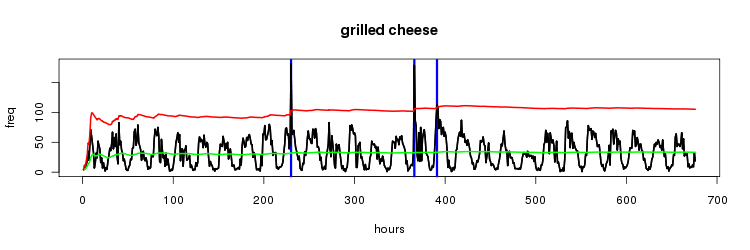
we get an interesting result from the very first spike at around 225... poor fangirl @rachelljonas spent 10 minutes tweeting like crazy trying to get the attention of @nickjonas (some popstar i've never heard of) and bumped up 'grilled cheese' for a single timeslot (here's her attempt to get his attention...)
this raises an interesting point about spam and should possibly my first pre processing data cleaning step. how should we disregard too many tweets from a single user in a timeslot?
the next spike at around 375 shows potentially my first true trending topic, a sudden increase in the discussion of making grilled cheese. the data has no dups so looks like it was just grilled cheese time!
cream cheese
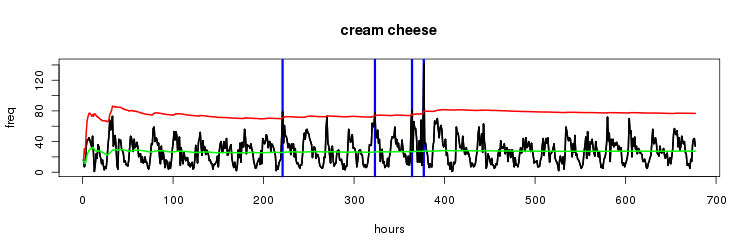
one major spike at about 376, looking at the data. there might have been a competition being run relating to #gno #bagelfuls ?
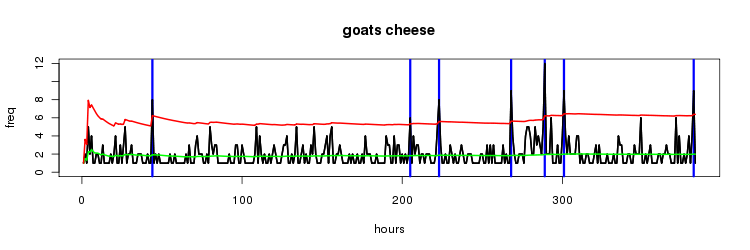
goats cheese
nothing uber interesting with the 'goats cheese' time series but it does illustrate an interesting point. for all the examples we've looked at so far each timeslot of an hour has included as least one entry for the 2gram. by the time we're getting to the less frequent ngrams we see as many timeslots with a zero frequency as with a non zero frequency.
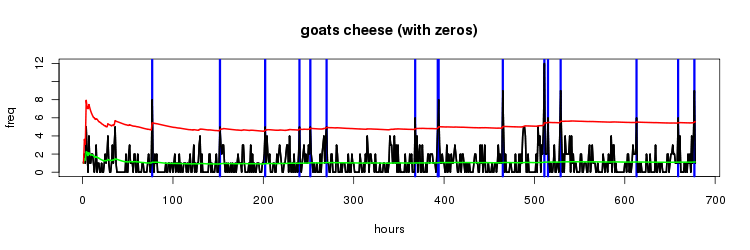
interestingly if you only consider the cases where the frequency values are non zero i think you get a better sense of where the values are trending.
this also turns out to make things easier to process :)
apple juice
with 'apple juice', an even less frequent 2gram, the effect is even more noticable if you ignore the zero frequency cases.
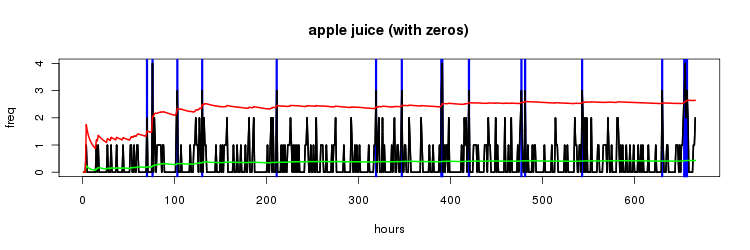
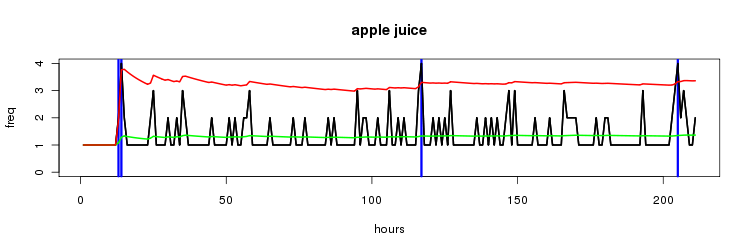
so with two ways of faceting the data, either timeslots or ngrams, the next step is porting the algorithm to pig so we can run it at scale, write up coming soon!
( code ( in a pretty raw form ) available at github )