





brain of mat kelcey...
collocations in wikipedia, part 1
October 19, 2011 at 08:00 PM | categories: Uncategorizedintroduction
collocations are combinations of terms that occur together more frequently than you'd expect by chance.
they can include
- proper noun phrases like 'Darth Vader'
- stock/colloquial phrases like 'flora and fauna' or 'old as the hills'
- common adjectives/noun pairs (notice how 'strong coffee' sounds ok but 'powerful coffee' doesn't?)
let's go through a couple of techniques for finding collocations taken from the exceptional nlp text "foundations of statistical natural language processing" by manning and schutze.
mutual information
the first technique we'll try is mututal information, it's a way of scoring terms based on how often they appear together vs how often they appear separately.
the intuition is that if two (or three) terms appear together a lot, but hardly ever appear without each other, they probably can be treated as a phrase.
a common definition for bigram mutual information is
\( MutualInformation(t1,t2) = log _{2} \frac{P(t1,t2)}{P(t1).P(t2)} \)
and a definition for trigram mutual information i found in the paper A Corpus-based Approach to Automatic Compound Extraction is
\( MutualInformation(t1,t2,t3) = log _{2} \frac{P(t1,t2,t3)}{P(t1).P(t2).P(t3)+P(t1).P(t2,t3)+P(t1,t2).P(t3)} \)
given a corpus we can use simple maximum likelihoods estimates to calculate these probabilities ...
\( P(t1,t2,t3) = \frac{freq(t1,t2,t3)}{\#trigrams} \) and \( P(t1,t2) = \frac{freq(t1,t2)}{\#bigrams} \) and \( P(t1) = \frac{freq(t1)}{\#unigrams} \)
so! we need a corpus! lets ...
- grab a freebase wikipedia dump
- pass it through the stanford nlp parser to extract all the sentences
- build the frequency tables for our ngrams
( see my project on github for the gory details to reproduce )
working with the 2011-10-15 freebase dump we start with 5,700,000 articles. from this the stanford parser extracts 55,000,000 sentences.
from these sentences we can extract some ngrams ...
| #total | #distinct | |
| unigrams | 1,386,868,488 | 8,295,593 |
| bigrams | 1,331,695,519 | 99,340,352 |
| trigrams | 1,276,522,552 | 381,541,510 |
the top 5 of each being...
|
|
|
(note: -RRB- is the tokenised right parenthese)
and, as always, the devil's in the detail when it comes to tokenisation... you always have to make lots of decisions; if we're after word pairs/triples should we just remove single characters such as '-' or '|' ? for this experiment i decided to leave them in as they act as a convenient seperator.
overall the freebase data is clean enough for some hacking. had to remove some stray html markup left in from the original wikimedia parse (so the stanford parser wouldn't implode) but other than that we can get away with ignoring anomalies such as the trigram '| - |' (hoorah for statistical methods!)
bigram mutual information
calculating the mutual information for all the bigrams with a frequency over 5,000 gives the following top ranked ones
rank bigram freq m_info 1 Burkina Faso 5417 17.88616 2 Rotten Tomatoes 5695 17.50873 3 Kuala Lumpur 6441 17.47578 4 Tel Aviv 9106 16.90873 5 Baton Rouge 5587 16.85029 6 Figure Skating 5518 16.44119 7 Lok Sabha 7429 16.43407 8 Notre Dame 13516 16.11460 9 Buenos Aires 20595 16.05346 10 gastropod mollusk 19335 15.92581 11 Costa Rica 11014 15.85664 12 Barack Obama 9742 15.84432 13 vice versa 5205 15.66973 14 hip hop 15727 15.63575 15 Uttar Pradesh 7833 15.63525 16 main-belt asteroid 10551 15.62005 17 Theological Seminary 6131 15.61613 18 Saudi Arabia 14887 15.59454 19 sq mi 8492 15.58054 20 São Paulo 13832 15.53181
these are pretty much all proper nouns and, though they are all great finds, they're not really the adjective/noun phrases i was particularly interested in. i guess it's not too surprising since we've done nothing in terms of POS tagging yet.
see here for the top 1,000
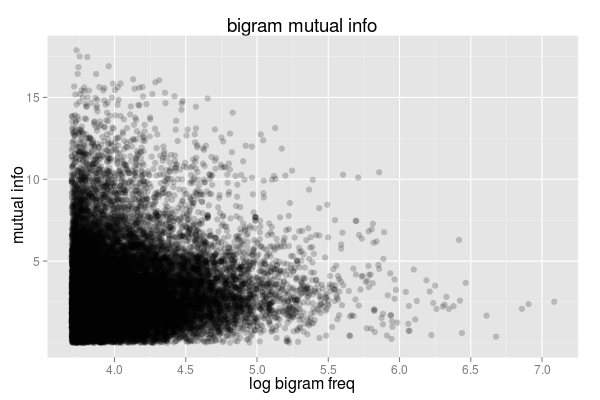
a plot of term frequency vs mutual information score shows an expected huge density of low frequency / low mutual information bigrams. the low frequency / high mutual info ones (in the top left) are the ones in the table above and the high frequency / low mutual info ones (in the bottom right) correspond to boring language constructs such as "of the", "to the" or ", and".
trigram mutual information
what about trigrams? here are the top 20 with a support of over 1,000
rank trigram freq m_info 1 Abdu ` l-Bahá 1011 19.06866 2 Dravida Munnetra Kazhagam 1043 18.98674 3 Ab urbe condita 1059 18.58179 4 Dar es Salaam 1130 18.09764 5 Kitts and Nevis 1095 18.02320 6 Procter & Gamble 1255 17.96789 7 Antigua and Barbuda 1290 17.90375 8 agnostic or atheist 1068 17.84620 9 Vasco da Gama 1401 17.77709 10 Ku Klux Klan 1944 17.77443 11 Ways and Means 1070 17.51264 12 Croix de Guerre 1196 17.46765 13 Jehovah 's Witnesses 2235 17.46177 14 SV = Saves 1980 17.24957 15 Venue | Crowd 1518 17.24024 16 summa cum laude 1363 17.22880 17 Teenage Mutant Ninja 1003 17.17236 18 Osama bin Laden 1734 17.16104 19 magna cum laude 1566 17.13729 20 Names -LRB- US-ACAN 2813 16.91815
again mostly proper nouns apart from some oddities such as "SV = Saves" (which must be from some type of sports glossary since i also see later "Pts = Points" & "SO = Strikeouts" )
see here for the top 1,000
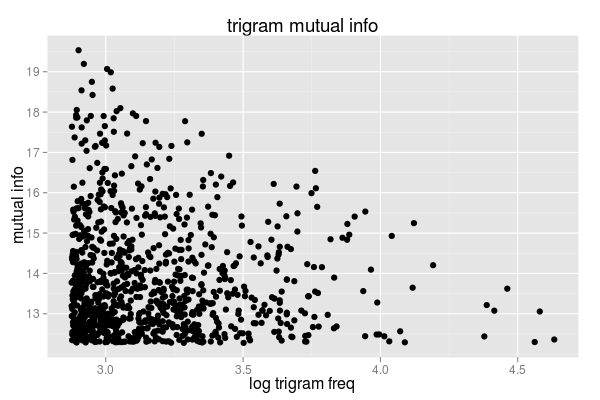
a plot of frequency vs mutual info is similar to the bigram case.
and the top 10 non capitilised trigrams are curious...
agnostic or atheist summa cum laude magna cum laude unmarried opposite-sex partnerships flora and fauna non-institutionalized group quarters mollusk or micromollusk italics indicate fastest air-breathing land snail
air-breathing land snails #ftw !
bigrams at a distance
a variation of the standard bigrams approach is to allow tokens to be treated as bigrams as long as they have no more than 2 tokens between them.
eg 'the cat in the hat' which would usually just have bigrams ['the cat','cat in', 'in the', 'the hat'] instead is defined by the bigrams ['the cat', 'the in', 'the the', 'cat in', 'cat the', 'cat hat', 'in the', 'in hat', 'the hat']
this results in roughly three times the bigrams (3,154,200,111 instead of 1,331,695,519) so it's slightly more processing but it allows tokens to influence each other at a short distance
calculating the mutual information for these bigrams gives a slightly different set
rank trigram freq m_info 1 expr expr 20888 17.04807 2 ifeq ifeq 6507 16.18608 3 Burkina Faso 5473 16.14546 4 Rotten Tomatoes 5705 15.75572 5 Kuala Lumpur 6457 15.72382 5 SO Strikeouts 5788 15.56487 6 Masovian east-central 8452 15.41213 7 Earned SO 5651 15.40456 8 Wins Losses 7984 15.23901 9 Tel Aviv 9137 15.15810 10 Baton Rouge 5599 15.09785 11 Dungeons Dragons 5509 14.84334 12 Trinidad Tobago 6241 14.77053 13 Figure Skating 5528 14.68826 14 Lok Sabha 7435 14.67970 15 background-color E9E9E9 8490 14.65283 16 Haleakala NEAT 5328 14.51430 17 Kitt Spacewatch 17854 14.43547
so more noise from the original freebase parse eg (expr, expr) or (background-color, E9E9E9)
interesting to see it picks up what would otherwise be a trigram with a middle 'and' eg (Dungeons, Dragons) and (Trinidad, Tobago)
summary
so we've found lots of proper nouns! these can be very useful if you're doing feature extraction for a classifier that doesn't like dependent features; a tokenisation of ['Barack Obama', 'went', 'to', 'Kuala Lumpur'] if often better than ['Barack', 'Obama', 'went', 'to', 'Kuala', 'Lumpur']
coming up next, the mean/sd distance method...