





brain of mat kelcey...
item similarity by bipartite graph dispersion
August 20, 2012 at 08:00 PM | categories: Uncategorizedthe basis of most recommendation systems is the ability to rate similarity between items. there are lots of different ways to do this.
one model is based the idea of an interest graph where the nodes of the graph are users and items and the edges of the graph represent an interest, whatever that might mean for the domain.
if we only allow edges between users and items the graph is bipartite.
let's consider a simple example of 3 users and 3 items; user1 likes item1, user2 likes all three items and user3 likes just item3.
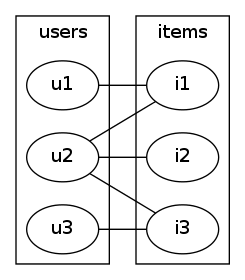 |
| fig1user / item interest graph |
one way to model similiarity between items is as follows....
let's consider a token starting at item1. we're going to repeatedly "bounce" this token back and forth between the items and the users based on the interest edges.
so, since item1 is connected to user1 and user2 we'll pick one of them randomly and move the token across. it's 50/50 which of user1 or user2 we end up at (fig2).
next we bounce the token back to the items; if the token had gone to user1 then it has to go back to item1 since user1 has no other edges, but if it had gone to user2 it could back to any of the three items with equal probability; 1/3rd.
the result of this is that the token has 0.66 chance of ending up back at item1 and equal 0.16 chance of ending up at either item2 or item3 (fig3)
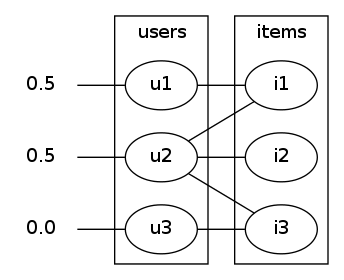 | 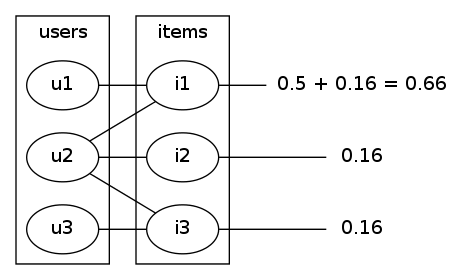 |
| fig2dispersing from item1 to users | fig3dispersing back from users to items |
( note this is different than if we'd started at item2. in that case we'd have gone to user2 with certainity and then it would have been uniformly random which of the items we'd ended up at )
for illustration let's do another iteration...
bouncing back to the users item1's 0.66 gets split 50/50 between user1 and user2. all of item2's 0.16 goes to user2 and item3 splits it's 0.16 between user2 and user3. we end up with fig4 (no, not that figure 4). bouncing back to the items we get to fig5.
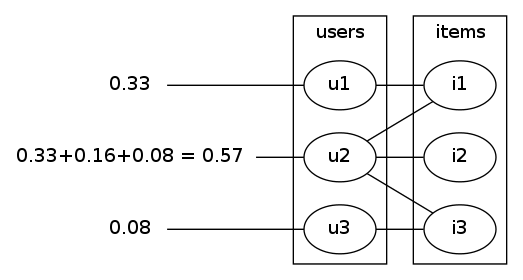 | 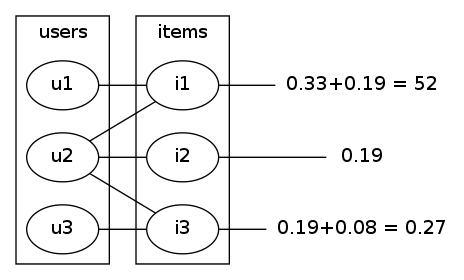 |
| fig4 | fig5 |
if we keep repeating things we converge on the values
{item1: 0.40, item2: 0.20, item3: 0.40} and these represent the probabilities of ending up in a particular item if we bounced forever.
note since this is convergent it also doesn't actually matter which item we'd started at, it would always get the same result in the limit.
to people familiar with power methods this convergence is no surprise. you might also recognise a similiarity between this and the most famous power method of them all, pagerank.
so what has this all got to do with item similiarity?
well, the values of the probabilities might all converge to the same set regardless of which item we start at but each item gets there in different ways.
most importantly we can capture this difference by taking away a bit of probability each iteration of the dispersion.
so, again, say we start at item1. after we go to users and back to items we are at fig3 again.
but this time, before we got back to the users side, let's take away a small proportion of the probability mass, say, 1/4. this would be 0.16 for item1 and 0.04 for item2 and item3. this leaves us with fig6.
| 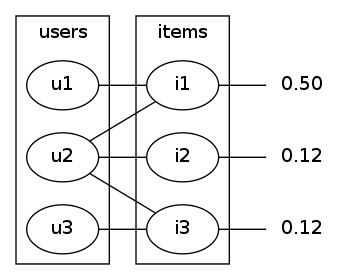 |
| fig3 (again) | fig6 |
we can then repeat iteratively as before, items -> users -> items -> users. but each time we are on the items side we take away 1/4 of the mass until it's all gone.
| iteration | taken fromitem1 | taken fromitem2 | taken fromitem3 |
| 1 | 0.16 | 0.04 | 0.04 |
| 2 | 0.09 | 0.04 | 0.05 |
| 3 | 0.06 | 0.02 | 0.05 |
| ... | ... | ... | ... |
| final sum | 0.50 | 0.20 | 0.30 |
if we do the same for item2 and item3 we get different values...
| starting at | total taken from item1 | total taken from item2 | total taken from item3 |
| item1 | 0.50 | 0.20 | 0.30 |
| item2 | 0.38 | 0.24 | 0.38 |
| item3 | 0.30 | 0.20 | 0.50 |
finally these totals can be used as features for a pairwise comparison of the items. intuitively we can see that for any row wise similarity function we might choose to use sim(item1, item3) > sim(item1, item2) or sim(item2, item3)
one last thing to consider is that the amount of decay, 1/4 in the above example, is of course configurable and we get different results using a value between 0.0 and 1.0.
a very low value, ~= 0.0, produces the limit value, all items being classed the same. a higher value, ~= 1.0, stops the iterations after only one "bounce" and represents the minimal amount of dispersal.