





brain of mat kelcey...
crazy large batch sizes
February 14, 2021 at 10:30 PM | categories: quick_hack, tpu, jax"use a bigger batch"
a classic piece of advice i hear for people using tpus is that they should "try using a bigger batch size".
this got me thinking; i wonder how big a batch size i could reasonably use? how would the optimisation go? how fast could i get things?
dataset
let's train a model on the eurosat/rgb dataset. it's a 10 way classification problem on 64x64 images

with a training split of 80% we have 21,600 training examples. we'll use another 10% for validation (2,700 images) and just not use the final 10% test split #hack
model
for the model we'll use a simple stack of convolutions with channel sizes 32, 64, 128 and 256, a stride of 2 for spatial reduction all with gelu activation. after the convolutions we'll do a simple global spatial pooling, a single 128d dense layer with gelu and then a 10d logit output. a pretty vanilla architecture of ~400K params. nothing fancy.
splitting up the data
a v3-32 tpu pod slice is 4 hosts, each with 8 tpu devices.
21,600 training examples total => 5,400 examples per host => 675 examples per device.
this number of images easily fits on a device. great.
augmentation
now usually augmentation is something we do randomly per batch, but for this hack we're interested in seeing how big a batch we can run. so why not fill out the dataset a bit by just running a stack of augmentations before training?
for each image we'll do 90, 180 and 270 deg rotations along with left/right flips for a total of 8 augmented images for each original image. e.g.....

this gives us now 172,800 images total => 43,200 per host => 5,400 per tpu device. which stills fits no problem.
side note: turns out doing this augmentation was one of the most fun parts of this hack :)
optimisers?
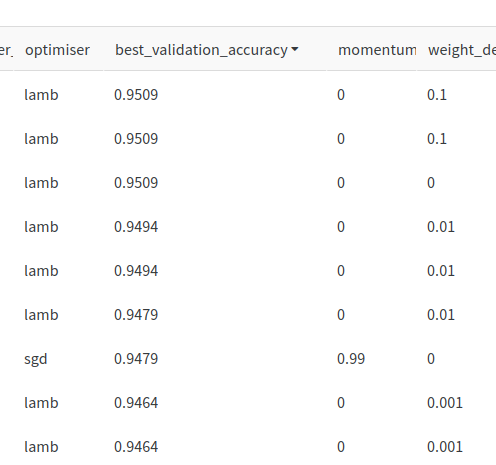
one motivation i had for this hack was to compare adam to lamb. i'd seen lamb referred to in the past, would it perform better for this model/dataset size? turns out it does! a simple sweep comparing lamb, adam and sgd shows lamb consistently doing the best. definitely one to add to the tuning mix from now on.
data / model / optimiser state placement
not only does the augmented data fit sharded across devices but we can replicate both the model parameters and the optimiser state as well. this is important for speed since the main training loop doesn't have to do any host/device communication. taking a data parallel approach means the only cross device comms is a gradient psum.
results
for training we run an inner loop just pumping the param = update(params) step.
an outer loop runs the inner loop 100 times before doing a validation accuracy check.
the inner loop runs at 1.5s for the 100 iterations and since each iteration is a forward & backwards pass for all 172,800 images across all hosts that's 11M images processed per second. 🔥🔥🔥
at this speed the best result of 0.95 on validation takes 13 outer loops; i.e. all done in under 20s. o_O !!
when reviewing runs i did laugh to see sgd with momentum make a top 10 entry.
new t-shirt slogan: "sgd with momentum; always worth a try"
code
all the code in hacktastic undocumented form on github