





brain of mat kelcey...
dithernet very slow movie player
October 21, 2020 at 10:30 PM | categories: gan, jax, projects, objaxvery slow movie player
it's been about two years since i first saw the awesome very slow movie player project by bryan boyer. i thought it was such an excellent idea but never got around to buying the hardware to make one. more recently though i've seen a couple of references to the project so i decided it was finally time to make one.
one interesting concern about an eink very slow movie player is the screen refresh. simpler eink screens refresh by doing a full cycle of a screen of white or black before displaying the new image. i hated the idea of an ambient slow player doing this every few minutes as it switched frames, so i wanted to make sure i got a piece of hardware that could do incremental update.
after a bit of shopping around i settled on a 6 inch HD screen from waveshare
it ticks all the boxes i wanted
- 6 inch
- 1448×1072 high definition
- comes with a raspberry pi HAT
- and, most importantly, support partial refresh
this screen also supports grey scale, but only with a flashy full cycle redraw, so i'm going to stick to just black and white since it supports the partial redraw.
note: even though the partial redraw is basically instant it does suffer from a ghosting problem; when you draw a white pixel over a black one things are fine, but if you draw black over white, in the partial redraw, you get a slight ghosting of gray that is present until a full redraw :/
dithering
so how do you display an image when you can only show black and white? dithering! here's an example of a 384x288 RGB image dithered using PILS implementation of the Floyd-Steinberg algorithm
 |
| original RGB vs dithered version |
it makes intuitive sense that you could have small variations in the exact locations of the dots as long as you get the densities generally right. s so there's a reasonable question then; how do you dither in such a way that you get a good result, but with minimal pixel changes from a previous frame? (since we're motivated on these screens to change as little as possible)
there are two approaches i see
1) spend 30 minutes googling for a solution that no doubt someone came up with 20 years ago that can be implemented in 10 lines of c running at 1000fps ...
2) .... or train an jax based GAN to generate the dithers with a loss balancing a good dither vs no pixel change. :P
the data
when building a very slow movie player the most critical decision is... what movie to play? i really love the 1979 classic alien, it's such a great dark movie, so i thought i'd go with it. the movie is 160,000 frames so at a play back rate of a frame every 200 seconds it'll take just over a year to finish.
note that in this type of problem there is no concern around overfitting. we have access to all data going in and so it's fine to overfit as much as we like; as long as we're minimising whatever our objective is we're good to go.
v1: the vanilla unet
i started with a unet that maps 3 channel RGB images to a single channel dither.
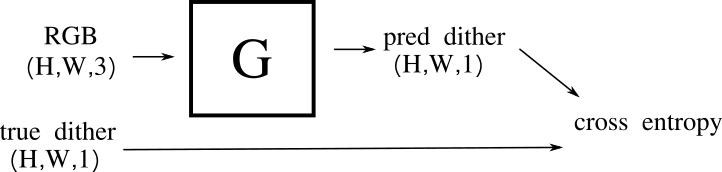 |
| v1 architecture |
i tinkered a bit with the architecture but didn't spend too much time tuning it. for the final v3 result i ended with a pretty vanilla stack of encoders & decoders (with skip connections connecting an encoder to the decoder at the same spatial resolution) each encoder/decoder block uses a residual like shortcut around a couple of convolutions. nearest neighbour upsampling gave a nicer result than deconvolutions in the decoder for the v3 result. also, gelu is my new favorite activation :)
for v1 i used a binary cross entropy loss of P(white) per pixel ( since it's what worked well for my bee counting project )
as always i started by overfitting to a single example to get a baseline feel for capacity required.

|
| v1 overfit result |
when scaling up to the full dataset i switched to training on half resolution images against a patch size of 128. working on half resolution consistently gave a better result than working with the full resolution.
as expected though this model gave us the classic type of problem we see with straight unet style image translation; we get a reasonable sense of the shapes, but no fine details around the dithering.

|
| v1 vanilla unet with upsampling example |
side notes:
- for this v1 version using deconvolutions in the decoder (instead of nearest neighbour upsampling) actually looked pretty good! nicely captured texture for a dither with a surprisingly small network.
- i actually did some experiments using branches in the decoder for both upsampling and deconvolutions but the deconvs always dominated too much. i thought that would allow the upsampling to work as a kind of residual to the deconv but it never happened.

|
| v1 vanilla unet with deconvolution example |
v2: to the GAN...
for v2 i added a GAN objective in an attempt to capture finer details
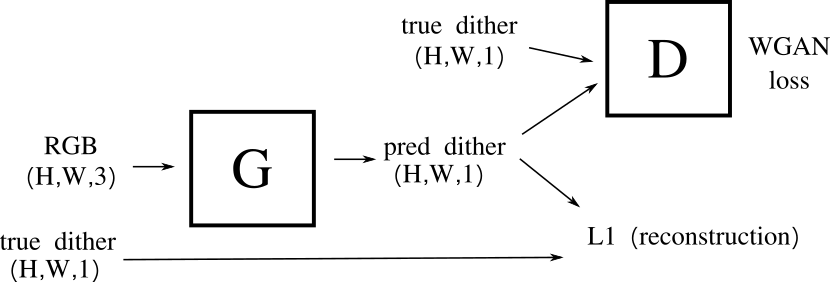
|
| v2 architecture |
i started with the original pix2pix objective but reasonably quickly moved to use a wasserstein critic style objective since i've always found it more stable.
the generator (G) was the same as the unet above with the discriminator (D) running patch based. at this point i also changed the reconstruction loss from a binary objective to just L1. i ended up using batchnorm in D, but not G. to be honest i only did a little did of manual tuning, i'm sure there's a better result hidden in the hyperparameters somewhere.
so, for this version, the loss for G has two components
1. D(G(rgb)) # fool D 2. L1(G(rgb), dither) # reconstruct the dither
very quickly (i.e. in < 10mins ) we get a reasonable result that is started to show some more detail than just the blobby reconstruction.

|
| v2 partial trained eg |
note: if the loss weight of 2) is 0 we degenerate to v1 (which proved a useful intermediate debugging step). at this point i didn't want to tune to much since the final v3 is coming...
v3: a loss related to change from last frame
for v3 we finally introduce a loss relating the previous frame (which was one of the main intentions of the project in the first place)
now G takes not just the RGB image, but the dither of the previous frame.
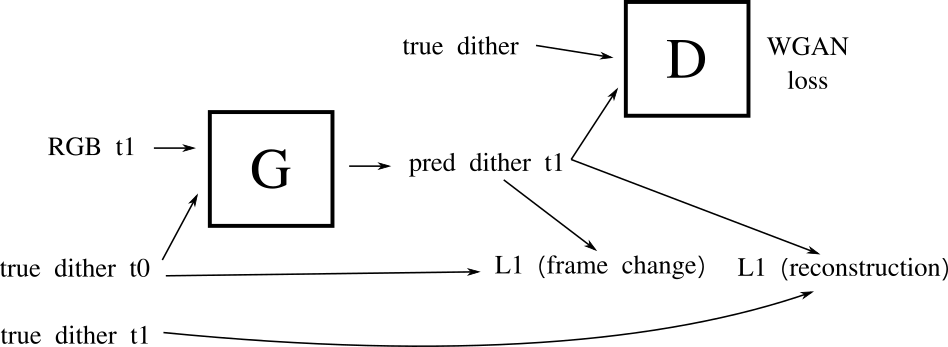
|
| v3 architecture |
the loss for G now has three parts
1. D(G(rgb_t1)) => real # fool D 2. L1(G(rgb_t1), dither_t1) # reconstruct the dither 3. L1(G(rgb_t1), dither_t0) # don't change too much from the last frame
normally with a network that takes as input the same thing it's outputting we have to be careful to include things like teacher forcing. but since we don't intend to use this network for any kind of rollouts we can just always feed the "true" dithers in where required. having said that, rolling out the dithers from this network would be interesting :D
digression; the troublesome scene changes
the third loss objective, not changing too many pixels from the last frame, works well for generally stationary shots but is disastrous for scene changes :/
consider the following graph for a sequence of frames showing the pixel difference between frames.
![]()
when there is a scene change we observe a clear "spike" in pixel diff. my first thought was to look for these and do a full redraw for them. it's very straightforward to find them (using a simple z-score based anomaly detector on a sliding window) but the problem is that it doesn't pick up the troublesome case of a panning shot where we don't have a scene change exactly. in these cases there is no abrupt scene change, but there are a lot of pixels changing so we end up seeing a lot of ghosting.
i spent ages tinkering with the best way to approach this before deciding that a simple
approach of num_pixels_changed_since_last_redraw > threshold was good enough to decide
if a full redraw was required (with a cooldown to ensure we not redrawing all the time)
... and back to v3
the v3 network gets a very good result very quickly; unsurprisingly since the dither at time t0 provided to G is a pretty good estimate of the dither at t1 :) i.e. G can get a good result simply by copying it!
the following scenario shows this effect...
consider three sequential frames, the middle one being a scene change.
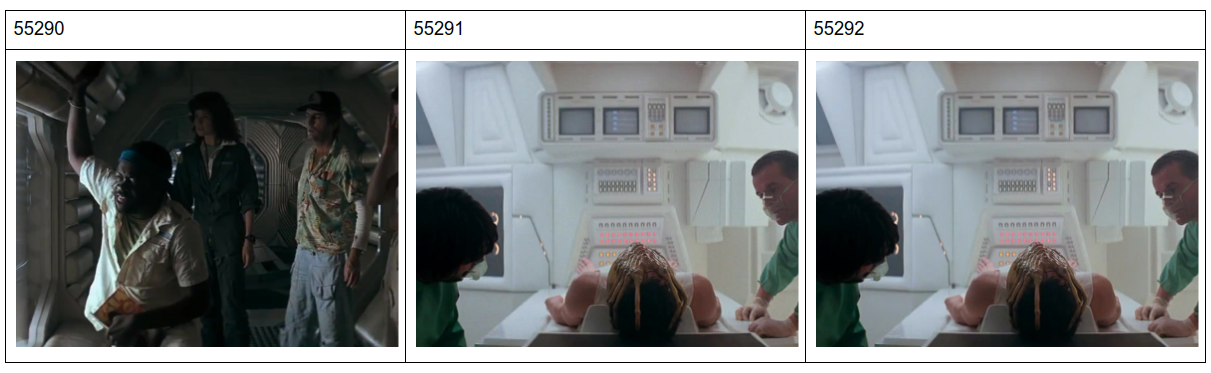
at the very start of training the reconstruction loss is dominant and we get blobby outlines of the frame.

but as the contribution from the dither at time t0 kicks it things look good in general but the frames at the scene change end up being a ghosted mix attempt to copy through the old frame along with dithering the new one. (depending on the relative strength of the loss terms of G).

the final result
so the v3 version generally works and i'm sure with some more tuning i could get a better result but, as luck would have it, i actually find the results from v2 more appealing when testing on the actual eink screen. so even though the intention was do something like v3 i'm going to end up running something more like v2 (as shown in these couple of examples (though the resolution does it no justice (not to mention the fact the player will run about 5000 times slower than these gifs)))
 |
 |
 |
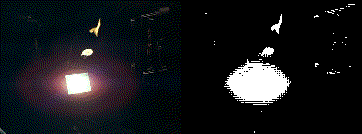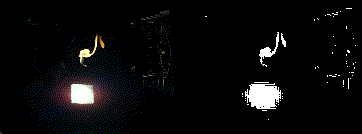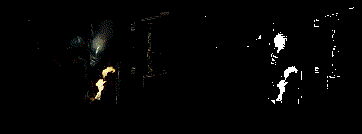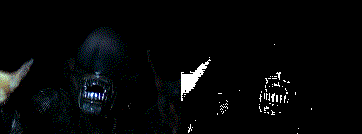 |
 |
 |
player case
i ran for a few weeks with a prototype that lived balanced precariously on a piece of foam below it's younger sibling pi zero eink screen running game of life. eventually i cut up some pieces of an old couch and made a simple wooden frame. a carpenter, i am not :/
 |
 |
| prototype | frame |
todos
- for reconstruction and frame change i used L1 loss, but that's not exactly what we want. since we want to avoid the ghosting (white changing to black resulting in grey) we should try to avoid white to black but ignore black to white.
- we might be able to better handle scene changes by also including a loss component around the next frame.
- there's a padding issue where i train G on patches but when it's run on the full res version we get an edge artefact the size of the original patch (see image below). as a hacky fix i just padded the RGB image before passing it to G in the final run, but this problem could be fixed by changing the padding schema during training.
